Matteo Visconti di Oleggio Castello, Ph.D.

I’m an Assistant Project Scientist in the Department of Neuroscience at the University of California, Berkeley, working in Jack Gallant’s lab. I’m interested in how our brains build and represent meaning from the world around us. My current research focuses on how these representations differ between people.
To study these questions, I build computational models to predict brain activity when we watch movies, listen to stories, or interact with each other. Then I break these models apart, and see if I can learn something interesting about the brain.
Before coming to Berkeley, I received a Ph.D. in Cognitive Neuroscience at Dartmouth, working with Ida Gobbini and Jim Haxby. At Dartmouth, I studied how our brains represent the identity of our friends and colleagues. I used psychophysics and fMRI to study familiar face perception.
News
- 2026-03-13 New preprint: Hyperface: a naturalistic fMRI dataset for investigating human face processing is available on bioRxiv. We released a comprehensive fMRI dataset of 21 participants watching 707 unique face video clips, along with code and three OpenNeuro datasets: raw data, fMRIPrep derivatives, and FreeSurfer derivatives.
- 2025-12-16 I released autoflatten, a Python pipeline for automatically creating cortical flatmaps from FreeSurfer surfaces. It features automatic cut mapping using surface-based registration (no manual cut placement required) and a new JAX-accelerated Python implementation of FreeSurfer’s mris_flatten algorithm that’s much faster than the original.
- 2025-11-18 I presented our work leveraging voxelwise encoding models to understand altered functional representations in frontotemporal dementia at SFN 2025 in San Diego.
- 2025-09-17 My latest paper on the Voxelwise Encoding Model (VEM) framework is available as a preprint on PsyArXiv. This paper provides the first comprehensive guide for creating encoding models with fMRI data, and complements our VEM tutorials.
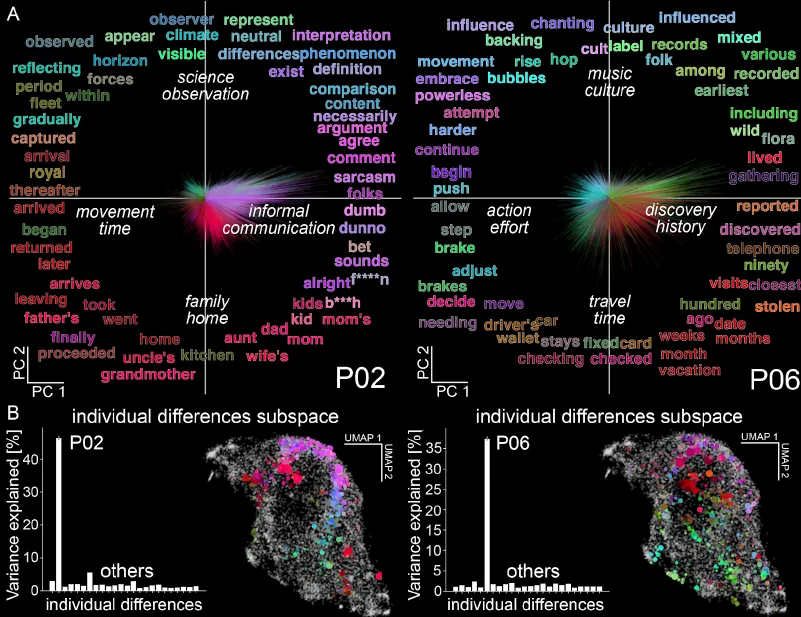
- 2025-08-23 My latest work on individual differences in conceptual representation is available as a preprint on bioRxiv. This paper introduces a new statistical framework to measure and interpret person-specific functional brain representations, establishing a new paradigm for precision neuroscience.
Selected publications
-
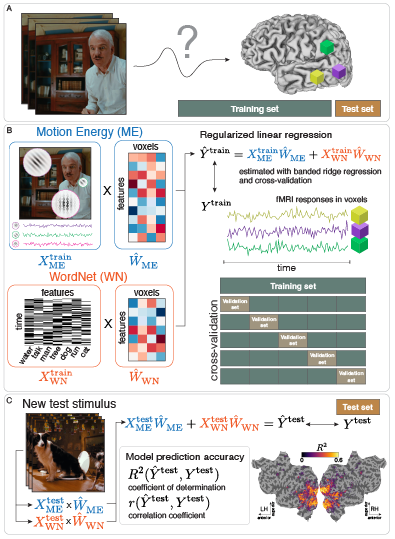 PsyArXiv, 2025* equal contribution
PsyArXiv, 2025* equal contribution -
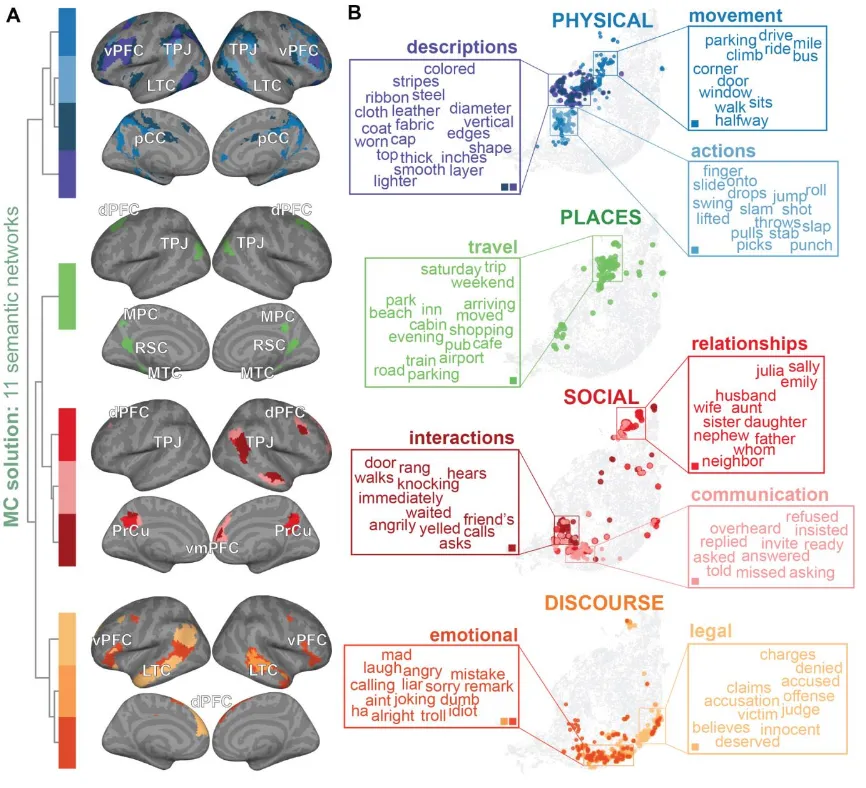 bioRxiv, 2023* equal contribution
bioRxiv, 2023* equal contribution
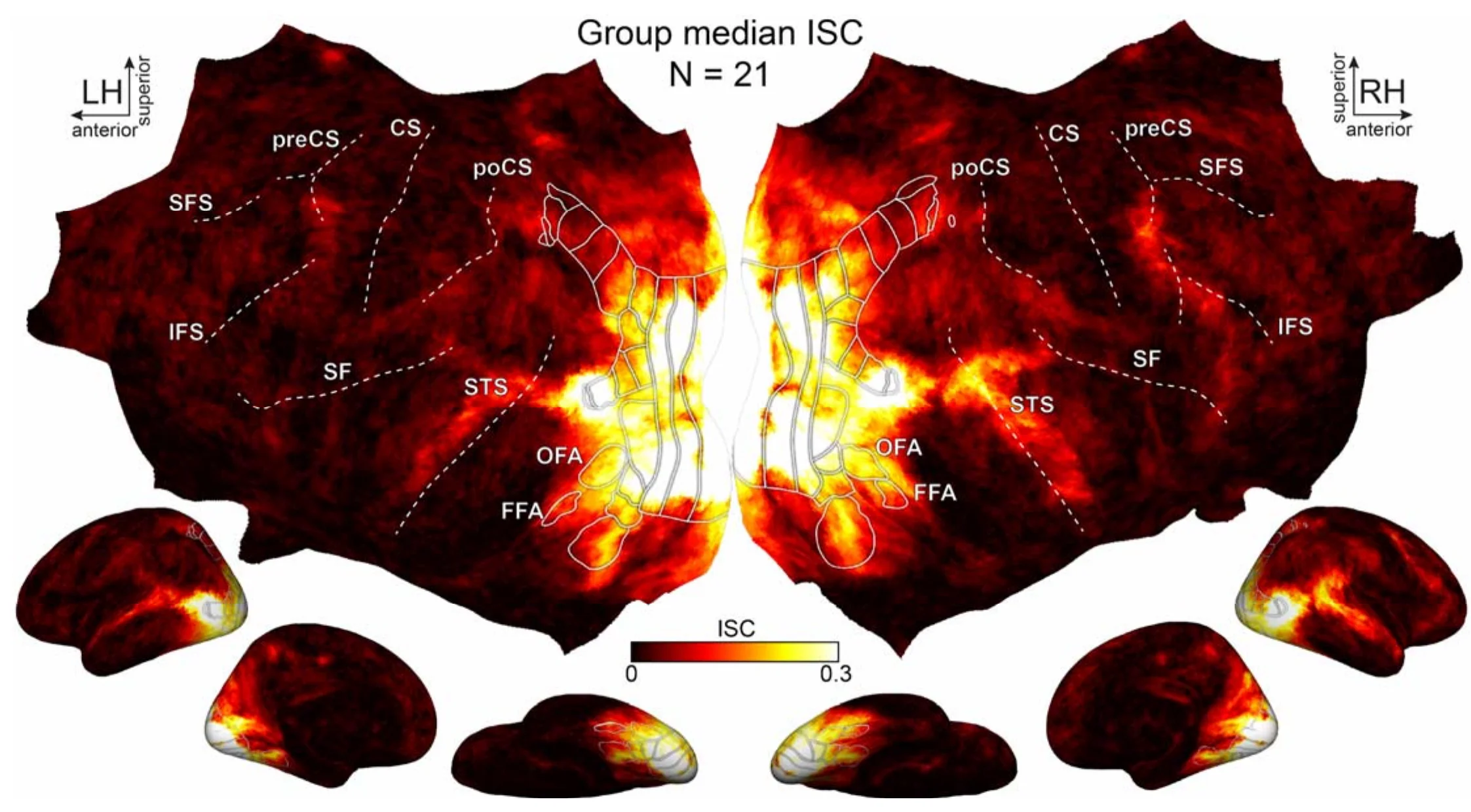
-
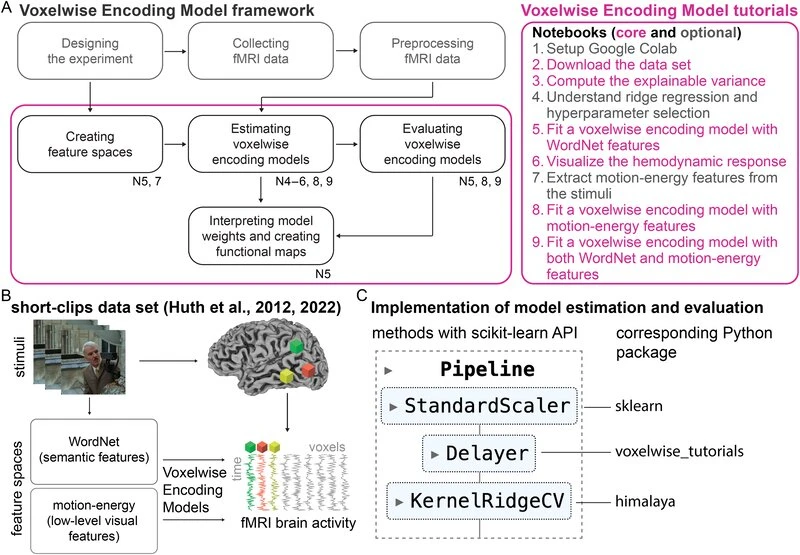 Imaging Neuroscience, 2025* equal contribution
Imaging Neuroscience, 2025* equal contribution -
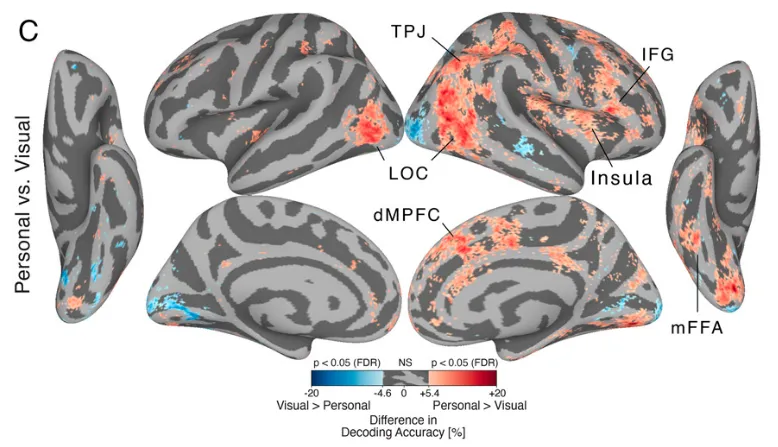 Proceedings of the National Academy of Sciences, 2021
Proceedings of the National Academy of Sciences, 2021 -
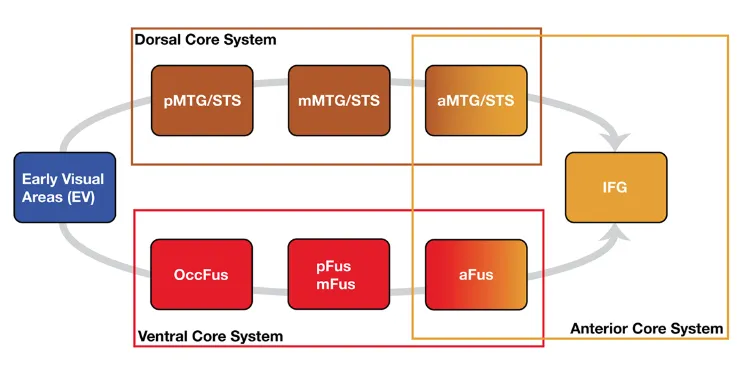 Scientific Reports, 2017* equal contribution
Scientific Reports, 2017* equal contribution